Use OpenCV’s CUDA DNN module and YOLOv4 model to accelerate real-time object detection with GPU
Introduction
Computer Vision is one of the main applications of current deep-learning-based AI wave. Compared to many AI research fields which are still in lab, CV is already largely deployed in production and used in all kinds of scenarios.
Originally developed by Intel and age 20 years now, OpenCV is a perfect tools for computer vision tasks.
In addition to traditional image processing use-cases such as image smoothing, edge detection, etc., OpenCV can also do Deep Neural Network inference. Thus, we can apply state-of-the-art computer vision NN models to project with the help of OpenCV.
Why choose OpenCV?
I have a hobby real-time object-detection project written in C++. After video frame is obtained, I’m facing the choice of frameworks suitable for object-detection on frame.
After investigation, I found that popular AI frameworks such as Tensorflow, Pytorch are stronger at training models. However, for an AI application, only inference part is important.
Since the project already uses OpenCV for other frame handling work, there is no need to import another AI framework and external project dependency is minimized.
Our friend of this task is DNN module. It provides support for deep learning inference. In the past, OpenCV only supports CPU inference which limits its usage, especially for real-time cases.
Fortunately, a sub-module named cuda4dnn is added recently which provides CUDA support for DNN. This sub-module is backed by NVIDIA’s cuDNN library, so inference performance on NVIDIA GPU shall be guaranteed.
code walk-through
The overall inference process is as follows:
1. load module
DNN supports multiple module formats including .pb(tensorflow), .onnx, etc. YOLO’s darknet model is also supported. To start, download pre-trained .weights file here.
Load the pre-trained weights with readNet:
cv::dnn::Net net_ = cv::dnn::readNet(weights_location, cfg_location);
2. set backend and target
DNN is a generalized inference engine supporting different backends including OpenCL, CUDA, FPGA, etc. Here we set CUDA as backend to use GPU for inference.
net_.setPreferableBackend(cv::dnn::Backend::DNN_BACKEND_CUDA);
net_.setPreferableTarget(cv::dnn::Target::DNN_TARGET_CUDA);
3. do inference
Use image blob as the input of DNN Net, do computation, then save the results in outs array:
cv::Mat blob = cv::dnn::blobFromImage(img, 1.0 / 255, cv::Size(320, 320), cv::Scalar(), true, false, CV_32F);
net_.setInput(blob);
std::vector<cv::Mat> outs;
net_.forward(outs, net_.getUnconnectedOutLayersNames());
Terminology
Mat
This is OpenCV world’s tensor/numpy-array, representing an n-dimensional array.
Data is wrapped inside Mat object and no manual garbage-collection is needed, just like std::vector. Data manipulation thus is much simpler than raw array.
Blob
The NCHW ordered 4-dimensional Mat transformed from input image. Blob served as the input of DNN Net.
4. NMS(Non-maximum Suppression) filtering
Object detection inference generates lots of similar candidate boxes. NMS is a technique that filters candidates. Here is what NMS process looks like:
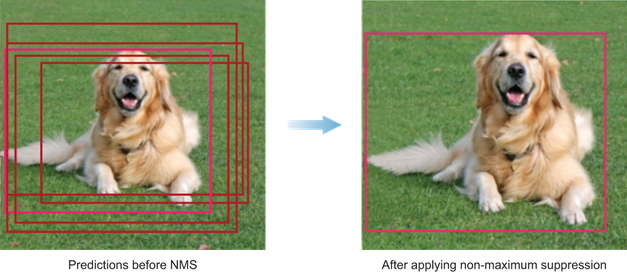
5. For each detection, draw a bounding box on frame
The following code loops over all detections and draws a bounding box with classification name and confidence on the frame.
for (size_t i = 0; i < indices.size(); ++i)
{
int idx = indices[i];
cv::Rect2d box = boxes[idx];
float conf = confidences[idx];
int class_id = classIds[idx];
add_bounding_box(class_names_, classIds[idx], confidences[idx], box.x, box.y, box.x + box.width, box.y + box.height, img);
}
We can use OpenCV to draw bounding boxes as well!
add_bounding_box(std::vector<std::string> &class_names, int classId, float conf, int left, int top, int right, int bottom, cv::Mat& frame)
{
cv::rectangle(frame, cv::Point(left, top), cv::Point(right, bottom), cv::Scalar(0, 255, 0));
std::string label = cv::format("%.2f", conf);
label = class_names[classId] + ": " + label;
int baseLine;
cv::Size labelSize = cv::getTextSize(label, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = cv::max(top, labelSize.height);
cv::rectangle(frame, cv::Point(left, top - labelSize.height),
cv::Point(left + labelSize.width, top + baseLine), cv::Scalar::all(255), cv::FILLED);
cv::putText(frame, label, cv::Point(left, top), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar());
}
cv::rectangle and cv:putText are 2 useful functions to help us draw bounding boxes and labels.
How DNN module is implemented internally
Let’s deep dive into OpenCV’s source code to see how DNN is implemented.
Net
This class represents an artificial neural network model.
readNet
This function loads model file into Net instance.
forward
The actual inference is done by this function. Let’s see what it looks like:
//source file: https://github.com/opencv/opencv/blob/7ce518106ba041f3cbb27cafda9eb670e5bb99f3/modules/dnn/src/dnn.cpp#L3802
void Net::forward(OutputArrayOfArrays outputBlobs, const String& outputName)
{
...
impl->setUpNet(pins);
impl->forwardToLayer(impl->getLayerData(layerName));
...
}
setUpNet is used to construct DNN Net for computation.
The forwardToLayer function is backed by specific backend node which does the concrete computation.
Layer
This class represents an abstract Neural Network Node. It is the building block of DNN Net.
BackendNode
Different backends inherits this class to provide different backend support of Layer.
How NVIDIA GPU is utilized by DNN module
As the above explanation indicates, cuda4dnn submodule provides CUDA backend support for DNN module. It implements abstract interfaces like BackendNode, and wrap concrete computation code inside.
Example: ReLU
ReLU is a typical activation function defined as: $f(x) = max(0,x)$
Let’s see how ReLU is implemented in cuda4dnn:
ReLUOp
ReLUOp is an implementation of CUDABackendNode.
//source file: opencv/modules/dnn/src/cuda4dnn/primitives/activation.hpp
template <class T>
class ReLUOp final : public CUDABackendNode {
public:
...
void forward(
const std::vector<cv::Ptr<BackendWrapper>>& inputs,
const std::vector<cv::Ptr<BackendWrapper>>& outputs,
csl::Workspace& workspace) override
{
for (int i = 0; i < inputs.size(); i++)
{
kernels::relu<T>(stream, output, input, slope);
}
}
...
};
When forward function is called, ReLUOp class proxies computation to kernels::relu. Definition of kernels::relu is as follows:
//source: https://github.com/opencv/opencv/blob/8808aaccffaec43d5d276af493ff408d81d4593c/modules/dnn/src/cuda/activations.cu#L126
template <class T>
void relu(const Stream& stream, Span<T> output, View<T> input, T slope) {
generic_op<T, relu_functor>(stream, output, input, slope);
}
CUDA kernel
A CUDA kernel of type relu_functor will then be generated by following function:
//source: https://github.com/opencv/opencv/blob/8808aaccffaec43d5d276af493ff408d81d4593c/modules/dnn/src/cuda/activations.cu#L30
template <class T, class Functor, std::size_t N, class ...FunctorArgs>
__global__ void generic_op_vec(Span<T> output, View<T> input, FunctorArgs ...functorArgs) {
using vector_type = get_vector_type_t<T, N>;
auto output_vPtr = vector_type::get_pointer(output.data());
auto input_vPtr = vector_type::get_pointer(input.data());
Functor functor(functorArgs...);
for (auto i : grid_stride_range(output.size() / vector_type::size())) {
vector_type vec;
v_load(vec, input_vPtr[i]);
for (int j = 0; j < vector_type::size(); j++)
vec.data[j] = functor(vec.data[j]);
v_store(output_vPtr[i], vec);
}
}
Launch kernel
Finally, the kernel will be launched by following function:
//source: https://github.com/opencv/opencv/blob/8808aaccffaec43d5d276af493ff408d81d4593c/modules/dnn/src/cuda/execution.hpp#L64
template <class Kernel, typename ...Args> inline
void launch_kernel(Kernel kernel, Args ...args) {
auto policy = make_policy(kernel);
kernel <<<policy.grid, policy.block>>> (args...);
}
ReLU Functor
Let’s see what the core ReLU logic looks like in relu_functor:
//source: https://github.com/opencv/opencv/blob/d981d04c76821037f745a3684533e753d6951e21/modules/dnn/src/cuda/functors.hpp#L92
template <class T>
struct relu_functor {
__device__ relu_functor(T slope_) : slope{slope_} { }
__device__ T operator()(T value) {
return value >= T(0) ? value : slope * value;
}
T slope;
};
We can see that cuda4dnn module actually implements Leaky ReLU variant. The signal can be leaked “backward” when input is from negative direction.

Comments